VOIP
Post mortem on the CommPeak VoIP services outage
February 26, 2024
1 min read

After a decade of uninterrupted service, this incident marks the first major outage experienced by CommPeak’s VoIP services.
On Monday, February 19th 1:11pm (UTC), CommPeak’s VoIP services experienced a degraded performance issue, eventually leading to a nearly complete outage of our global PoPs (Point of Presence). The incident has affected SIP termination and origination services, Dialer and PBX services.
CommPeak’s network has 10 “edge” PoPs, where each PoP combines a SBC AAA component (Session Border Controller Authentication, Authorization, and Accounting), Routing engine and RTP components for Audio relay and transmission. The failure was at our root routing engine database.
Due to a software bug triggered at our AAA and Routing manager, our database began experiencing a corruption which made existing routing configurations to become invalid.
At 1:27pm, we began stopping the origin database to replicate and apply its invalid configuration changes on our PoPs. At this point, some of our PoPs were already updated with invalid configuration and began rejecting calls with SIP error 503 and others accepted some of the incoming traffic requests, where approximately 30% of the calls were rejected with SIP error 503 (Temporary Service Unavailable, Destination Unreachable).
At same time we also began database restoration procedures in 2 different ways as an attempt to find the shortest time for recovery. At 4:49pm we repaired our routing origin database, and began to replicate the changes to our network. Due to redundancy configuration this process lasted more than expected. We brought some of the PoPs to production starting at 6pm and restored all of them at 2am.
On Tuesday, February 20th at 7:30am, we observed that the restoration process caused a new performance degradation in one of the queries being executed against the routing database, hence causing high PDD (Post Dial Delay), network to go out of sync again and reject calls. This degradation was mainly caused by calls within the EEA and primarily affecting several destinations within Europe, where APAC and America were less affected.
We began working on finding a solution to overcome the problematic query issue, which was resolved at 10:12am and the fix was deployed to all the PoPs, however this issue degraded some of the PoPs which were disabled until we fully recovered them.
On Tuesday, 10:30am, our network was at complete health, all services were restored and we confirmed our customers were no longer affected.
This post outlines the events that caused this incident, the architecture we had in place, what failed and what worked and why, and the changes we are making based on what we’ve learned over this incident.
To start, this never should have happened. We believed that we had high availability systems in place that should have stopped an outage like this. We also believed our network failovers and backup protocols had much quicker recovery times. We have also not properly reflected this issue in a timely manner, as we expect from ourselves. I am sorry for this incident and the pain that it caused our customers and our teams.

CommPeak provides its services to customers with redundancy and latency sensitivity in mind. CommPeak carries 10 VoIP PoPs (Point of Presence) and additional 5 service PoPs worldwide – North America, South America, Europe, South Africa, APAC and Australia.
Each VoIP PoP is made from at least three layer of services:
Each VoIP PoP can make its decisions of call acceptance and routing based on customer information within the network (Number of Calls, Volumes, Anti-fraud measurements) from certain origin roots.
A VoIP PoP can also make its decisions independently, in order to accelerate the PDD (Post Dial Delay) of customers, based on replicated databases and analytics created within the PoP (health state of root databases, fraud control information and more).
Each PoP-
Knowing that there is no such thing as a datacenter with no failure, let it be a power or network connectivity issue, we have created our PoPs that can work independently in case of a failure in our core services or assisted services.
This design allows us to perform maintenance on our core components without affecting the connectivity of our network.
Our routing database is responsible for deciding how calls will be routed and connected to the upstream networks, based on the origin decision of where the call comes from.
For example, a routing decision can be such as- Platinum plan (Tech Prefix 021001), with the following (invalid) number +440000366665, should be sent to the following upstream European carriers: BT, Orange, Lycamobile. BUT if the call is originating from South America, then also add other regional carriers, such as Telefonica and Entel, to the possibility of upstream routing options.
Our routing is combined from both the originating source of call and the destination number, in addition to the customer parameters and calling plan.
Due to a software bug triggered at our AAA and Routing manager, a component which is used by our teams, we began noticing that our routing decisions and simulations within our management tools along with automated health checks were malfunctioning, due to a corruption caused by the bug.
The corruption has made a part of our routing data to be invalid, thus, will cause new incoming calls to be rejected due to lack of proper routing information.
At 1:27pm, we began stopping the origin database to replicate and apply its new (invalid) changes on our PoPs. At this point, some of our PoPs were entirely invalid and began rejecting all calls with 503 and others accepted some of the incoming traffic requests, where approximately 30% of the calls were rejected with SIP error 503 (Temporary Service Unavailable, Destination Unreachable).
We realized that the most accurate way to restore the routing data as a whole was to restore a daily backup, where its most recent backup (from a few hours earlier) was a full backup. Since it’s a time consuming operation due to the size of the specific backup (TBs compressed image), we began working in parallel on restoring functionality, by fixing the origin database starting with the most popular routes in order to keep the service up and running.
We have speculated that some of our PoPs are healthy and some are broken. Those who are broken send a failover signal (SIP 503) to the call initiators (customers VoIP switches and our own retail solutions software). The failover signal will failover the call to another PoP which is healthy.
At this point, we have begun performing DNS changes to our network in order to create proper primary and secondary in an attempt to route calls to “more” healthy PoPs. For example, we have applied a DNS change for eu2.sip.commpeak.com to point to the IP of eu1.sip.commpeak.com, which we determined was in a more healthy state.
At 4:49pm we brought our routing database back to a fully operational and healthy state. Our goal was to connect our edge PoPs back to its root database, replicate all the data and restore network health.
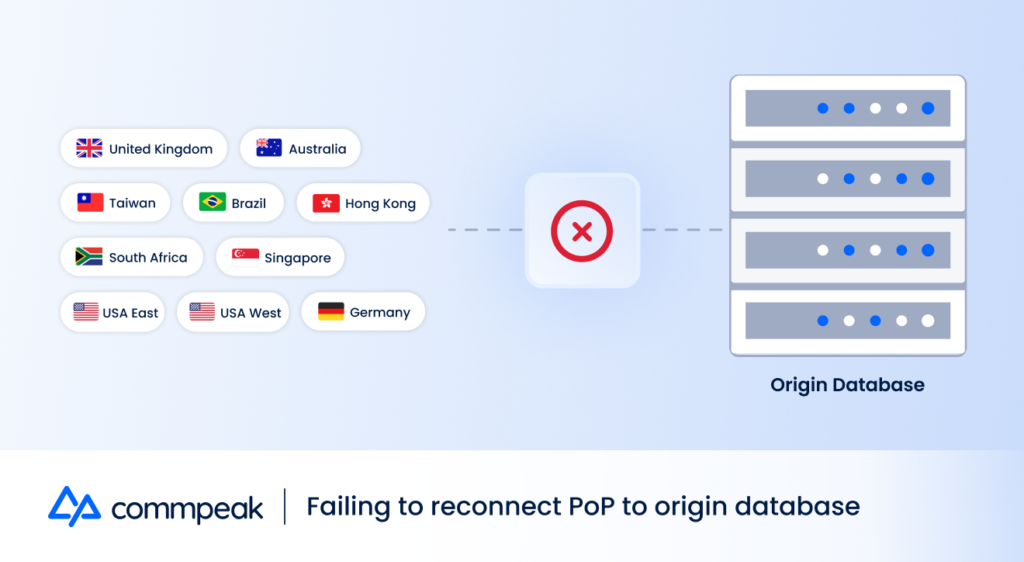
Because of our earlier attempt to stop the spread of the corrupted information, we had to break the real-time database replication from our root database to our PoPs. After performing such a break, and due to the split-brain we intentionally caused to our PoPs, we had to rebuild the local database and reconnect the replication from scratch.
Our procedure in the case of a faulty PoP-
The process of reconnecting a replication is done by copying an updated snapshot of the database to the replicated server and connecting to master. The process requires a downtime of the PoP database server, and a necessary time to transfer a relatively large database.
Our challenges were rejection of the origin server to accept the newly connected databases, transfer times and times where the newly replicated database received old corrupted entries.
During the course of time we have restored different PoPs to functionality, where the entire process was completed at 2:00am (Tuesday, February 20th 2023).
On Tuesday, February 20th 2023 at 7:30am we noticed an intense load in our European region and began to investigate. We have found that certain routing destinations have made our database queries to be extremely slow. This caused high calls to PDD and AAA timeouts. For some reason, the scenario also caused some of our replications to break entirely.
At first we have seen unexplained performance issues with our European PoPs, where Asia was not affected from the observation at the time. We suspected an issue with our replicated data, and we therefore decided to connect the European region to a centralized point near our core, to overcome this issue. This is not a plan we have executed before, and we have experienced challenges related to latency, VPNs, firewalls and more, associated with our network.
After connecting the European PoPs to the new database, we saw the same load on the connected database, and saw that certain amount of call requests are answered only after an unreasonable amount of time.
We engaged with our DBA team to analyze and overcome the problematic query issue. For better redundancy we are using different data centers across the world, meaning our servers have different hardware configurations, which increases the complexity of the resolution, it should fit all setups across the network. Our engineers identified and created a patch for the problematic query and at 10:12am we completed patching the faulty routing query code across all servers, deploying the hotfix and restoring each PoP to its local replicated database. At this point of time all our customers were unaffected by any issue.

While obviously this is not our first incident, this incident showed us that we were not fully communicating the issues properly to our teams, hence to our customers. We also saw that while there were some benefits to our architecture design, there are downsides especially in terms of recovery from corruptions in origin “source of truth” points. Also, while we did find our backup procedures to be efficient, we have realized our restoration processes are longer than expected and must be improved.
We now plan to expect the following changes:
We do understand the incident and the pain that it caused to our customers. We have the right systems and procedures in place to be able to withstand even the cascading string of failures occurring, but we need to be more rigorous about enforcing that they are followed and tested properly. This will have our full attention and the attention of a large portion of our team through the balance of the year.

